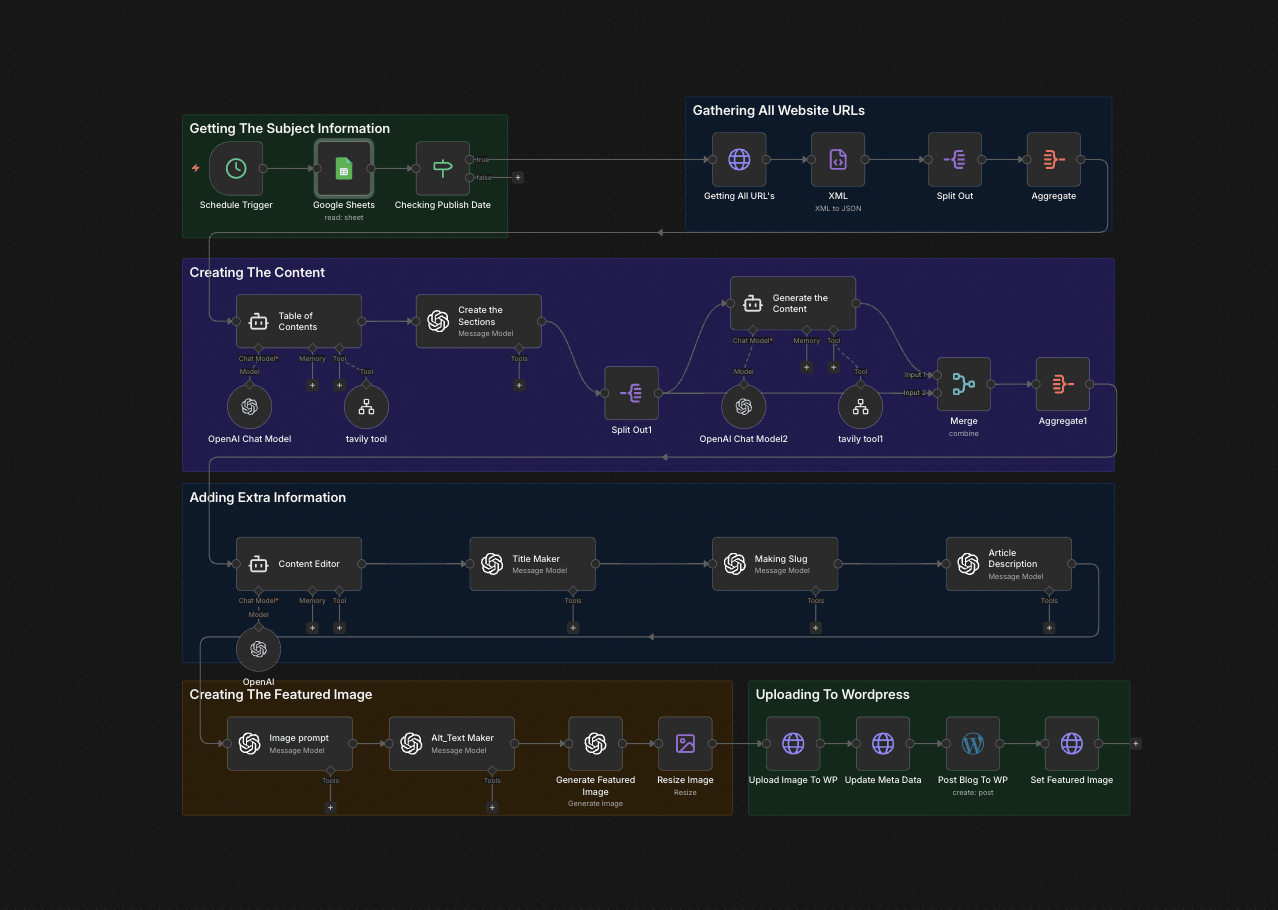
The full n8n canvas as it runs in production.
The Content Team That Can't Scale
Most B2B content teams hit the same ceiling. Two writers, eight articles a month each, sixteen total. The CEO wants forty. Hiring more writers takes three months and costs $80K-$120K loaded per hire. The keyword backlog grows faster than the team can publish.
AI alone doesn't fix this. Generic GPT articles rank badly because they have no real research, weak SERP-targeting, and no internal links to existing content. They feel synthetic. Google notices.
The fix is a structured pipeline. Real research from a search tool. SERP intent analysis. Section-by-section drafting with explicit structural requirements. AI-generated featured images. Auto-mapped internal links to your existing content. WordPress publish on completion.
Output is articles that read close to human-written, target SERP intent accurately, and ship at 10× the cost-effectiveness of writers alone. The content team's job becomes editorial review and strategic keyword selection — not assembling drafts from scratch.
From Keyword to Published
Built on n8n. Keywords live in a Google Sheet with status flags. The workflow reads rows marked Ready, runs Tavily research with SERP-aware queries, and pulls top-10 SERP results via Apify for intent analysis. GPT-4o-mini reads the SERP and writes a structural outline. Each section drafts independently with research grounding.
The drafted article runs through Claude for voice and tightness. DALL-E 3 generates a featured image based on the article's topic and brand style. The internal-link node queries WordPress for related published posts and inserts contextual links. The WordPress API publishes as a draft (or live, if configured), and the Sheet row updates to Published.
From Keyword to Published Post: Six Steps
Keyword Trigger
Cron node reads the Google Sheet daily. Picks rows where Status = Ready and Target Date matches today. Each keyword has metadata — search intent, target word count, internal anchor list.
Research and SERP Analysis
Tavily runs deep research on the keyword. Apify scrapes the top 10 SERP results and extracts headers, structure, and key claims. The SERP analysis informs the article's structural decisions.
Outline Generation
GPT-4o-mini reads the research and SERP analysis and outputs a structural outline — H2s, H3s, target word counts per section, internal anchor opportunities. The outline matches SERP intent without copying competitors.
Section Drafting
Each section drafts independently using research findings as ground truth. Sections write in parallel where possible. Word counts respect the outline's targets.
Voice Refinement and Image
Claude refines the full draft for voice, rhythm, and tightness. DALL-E 3 generates a featured image based on the topic and brand style guide. Both run in parallel.
WordPress Publish
The draft, image, metadata, and auto-mapped internal links assemble. WordPress REST API publishes as draft for editorial review (default) or live (configured). The Sheet row updates to Published with the post URL.
What This Pipeline Does That AI Drafts Don't
SERP-Targeted Outlining
Real SERP analysis informs every article's structure. Articles match search intent without copying competitor content.
Two-Model Drafting
GPT-4o-mini drafts. Claude refines. The combination produces tighter prose that reads closer to human-written than either model alone.
Auto-Mapped Internal Linking
The pipeline queries WordPress for related published posts and inserts contextual internal links automatically. Helps SEO and reduces editorial overhead.
Featured Image Generation
DALL-E 3 generates a featured image per post matching the brand style. No more 'we forgot the hero image' moments.
Editorial Queue Mode
Default behaviour is publish-as-draft. Editors review before going live. The pipeline never publishes anything to live without explicit configuration.
Cost Per Article Visible
Token usage logs per article. Most full-length posts cost $1.50-$5.00 in LLM and image generation fees. Compare to $200-$600 per article for human writers.
Before vs. After: What Changes When the Pipeline Writes
Two writers, sixteen articles a month, $9,600 total cost. The CEO's keyword backlog is at 200 and growing. Three articles take two weeks to publish because of brief writing, drafting, editing, image sourcing, WordPress formatting, and internal linking handoffs.
Forty articles a month with the same two writers in editorial mode. Cost per article drops from $600 to $160. Time from keyword-Ready to draft-Live drops from a week to under two hours. The keyword backlog clears in five months instead of compounding forever.
Live in 4 Weeks
Days 1-5 — Brand Voice and Style Capture
We read 12 of the team's best articles. Codify voice rules, structural patterns, and brand tone. Build the Claude refinement prompt. Set up the brand style guide for image generation.
Days 6-12 — Research and Drafting
Wire Tavily, Apify SERP scraping, and the GPT-4o-mini outlining and drafting layer. Run the first three test articles against held-out brand examples for voice match.
Days 13-21 — WordPress and Internal Linking
WordPress REST API integration. Featured image generation. Internal link mapping against the existing content corpus. Editorial draft mode by default.
Days 22-28 — Calibration and Cutover
Five articles ship in supervised mode. Editors review and give feedback. We tune voice rubric, SERP targeting, and internal link mapping. By article 6, editors only edit 5-10% of drafts.
The Right Fit — and When It Isn't
Right fit for B2B content teams with a keyword strategy and a backlog they can't clear with current headcount. Works best when the team has 50+ existing published articles to anchor voice and internal linking against.
Not a fit for thought-leadership content built on original interviews or proprietary data. Not a fit for highly regulated industries (healthcare, legal, financial advice) where every claim needs human compliance review — though the pipeline still drafts, the editorial overhead stays close to fully human.
Frequently Asked Questions
Will Google penalise AI-generated content?+
Google's policy is that helpful, original content ranks regardless of how it's produced. The pipeline outputs articles with real research, SERP-targeted intent, internal links, and brand voice — which is what 'helpful' means in practice. We've not seen ranking penalties on properly-edited output.
Can it publish to Webflow or Ghost instead of WordPress?+
Yes. The publish node is a single swap. We've shipped versions targeting Webflow, Ghost, Sanity, and Contentful. WordPress is the default because it's most common.
How does it handle internal linking to articles that don't exist yet?+
The pipeline queries the live WordPress index at draft time. If a relevant target doesn't exist, the link is skipped and a TODO comment appears in the editorial queue.
What's the cost per article fully loaded?+
$1.50-$5.00 in LLM, search, and image generation fees. Plus editorial review time, which drops to about 10 minutes per article once voice is locked. Total cost per article: $160-$200 vs. $600+ for fully human production.
Stop capping content at what two writers can type.
Book a Pipeline Audit. We'll review your keyword backlog, scope the publishing layer, and quote a build that 10× your output without hiring.