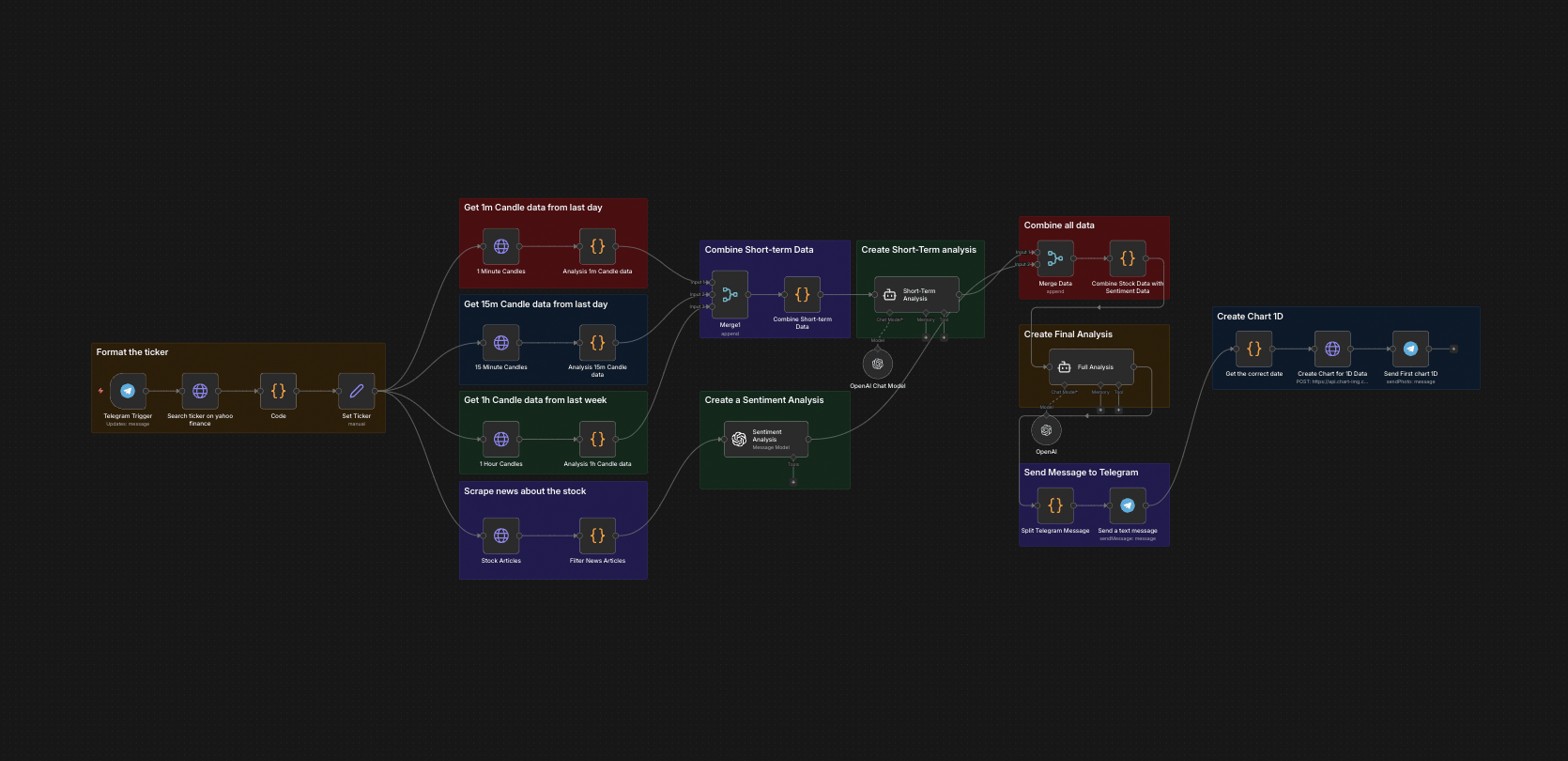
The full n8n canvas as it runs in production.
Most Bad Trades Come From Emotional Pattern-Matching
Every active trader has the same failure mode. They have a defined edge — specific setups, specific timeframes, specific entry rules. On a calm day, they execute the edge. On a chaotic day, they second-guess, force trades, or skip valid setups because of recent losses. The edge is real; the discipline is the bottleneck.
AI doesn't predict the market. It does something more useful — it applies the trader's own rules consistently across hundreds of names without fatigue or emotion. The edge stays human. The execution gets disciplined.
Two failure modes break manual day trading. First, attention is finite — even a sharp trader can only watch 5-7 names. Setups in name #20 don't get caught. Second, emotional state distorts judgement — after a loss, the trader either freezes or revenge-trades. Both cost.
This system codifies the trader's edge into a structured rubric. Then it scans the configured market continuously, identifies setups that match, and ships structured trade tickets to Telegram with entry, target, and stop. The trader reads, validates, and decides. The agent doesn't trade — the human does. But the agent does what the human can't: scan 200 names every minute without bias.
From Market Tick to Trade Ticket
Built on n8n. A scheduled trigger fires every minute and pulls market data for the configured watchlist (typically 100-300 names). For each name, indicator calculations run — moving averages, RSI, volume profile, support/resistance levels. The trader's setup rubric evaluates against the calculated indicators.
Setups that match generate a draft trade ticket — entry price, stop level, target, position size, and a confidence score. GPT-4o-mini reads the setup context and writes a one-paragraph thesis explaining the trade. Output ships to Telegram. The trader validates and decides whether to execute. No automated execution by default — the human stays in the loop.
From Tick to Ticket: Six Steps
Market Data Pull
Cron fires every minute. Pulls latest price, volume, and order-book data for the watchlist via Yahoo Finance, Finnhub, or broker API. Data caches in a rolling window for indicator calculation.
Indicator Calculation
Moving averages (20/50/200), RSI, volume profile, support/resistance levels, and any custom indicators the trader specified all calculate per name. Output is a structured indicator object.
Setup Rule Evaluation
The trader's rubric — codified as configurable rules — evaluates against each name. Rules can stack ('RSI < 30 AND price near 200MA AND volume > 1.5× average'). Matched setups get flagged.
Risk Sizing
Each flagged setup calculates position size based on the trader's risk-per-trade rule (e.g. 1% of account per trade) and the stop distance. Output is a concrete share/contract count, not just an idea.
Thesis Generation
GPT-4o-mini reads the setup context and writes a 3-4 sentence thesis — what the setup looks like, what would invalidate it, what the catalyst could be. Honest framing.
Telegram Delivery
Trade ticket ships to Telegram with ticker, entry, stop, target, position size, confidence score, and thesis. Optional one-click 'show me the full chart' or 'compare to similar setups today' drill-downs.
What This Agent Does That Manual Scanning Can't
Continuous Coverage
Scans 200+ names every minute. The trader's manual coverage limit (5-7 names) becomes irrelevant — the agent watches everything in scope.
Disciplined Rule Execution
Codified rules execute the same way regardless of the trader's emotional state. After a loss, the agent still flags the next valid setup.
Risk-Sized Tickets
Every ticket includes the position size for the trader's specific risk-per-trade rule. No more 'how much should I size this' anxiety.
Honest Confidence Scoring
Each ticket includes a confidence score based on how cleanly the setup matches the rubric. High-confidence setups stack out. Low-confidence setups still surface but flag clearly.
Backtest Against Historical Days
Every rule the trader codifies can replay against historical market data. The trader sees how often the rule would have fired and what the outcomes looked like before going live.
Trader-in-the-Loop by Default
No automated execution unless explicitly enabled. The agent flags. The trader decides. The discipline benefit comes from consistent rule execution, not removing the human.
Before vs. After: What Changes When Discipline Scales
Trader scans 6 names manually. Two valid setups all morning, both taken — one wins, one loses. After the loss, trader feels off and skips a third setup later that turns out to be valid. End of day: 1 trade, 50% win rate, 3 missed setups.
Agent scans 200 names. Eight valid setups flag throughout the day with thesis and risk sizing. Trader takes 5, skips 3 that don't fit risk parameters. Win rate stays consistent because every setup taken is rule-validated, not emotion-validated. Position size is right because the agent calculated it.
Live in 5 Weeks
Week 1 — Edge Codification
We sit with the trader and codify their edge into structured rules. What's the setup? What's the entry trigger? What's the stop logic? What invalidates the trade? This step is the most important — bad rubric means bad output.
Week 2 — Indicator and Data Layer
Wire market data feeds. Build the indicator calculations the trader's rubric depends on. Verify cached data accuracy against the trader's manual TradingView.
Week 3 — Rule Engine and Risk Sizing
Build the rule evaluation engine. Wire risk sizing per the trader's account configuration. Test against backtests of the last 60 days.
Week 4 — Thesis and Telegram
Wire GPT-4o-mini thesis generation. Build Telegram delivery. Run shadow mode for one week — agent flags but trader trades manually as before.
Week 5 — Calibration and Cutover
Compare shadow alerts to what the trader actually traded. Tune the rubric. Lock the rules. Go live with the trader using the agent as primary scanner.
The Right Fit — and When It Isn't
Right fit for active day traders, swing traders, and small prop desks with a defined and codifiable edge. The trader needs to articulate clear rules — entry, stop, target, invalidation. Vague setups can't be coded.
Not a fit for discretionary traders whose edge is pattern intuition that doesn't translate to rules. Not a fit for HFT — minute-resolution architecture is too slow. Not a fit for novice traders without a tested edge — the agent will execute the wrong rubric at scale and lose money systematically.
Frequently Asked Questions
Will this trade for me automatically?+
Only if you explicitly enable it. Default is alert-only. If you want automated execution, we wire in pre-trade checks (account equity, position concentration, drawdown limits) and broker integration. Most clients keep humans in the loop.
What happens during a flash crash or extreme volatility?+
Configurable circuit breakers — drawdown limits per day, max number of trades per session, suspension on extreme volatility events. The agent stops flagging when conditions are outside the trader's tested regime.
How do you backtest the rubric?+
We replay the last 60-180 days of market data through the rule engine. The trader sees how often each setup fired, average outcome, and worst-case drawdown. Most traders refine their rules during this step before going live.
Can this work for futures or forex?+
Yes. Equities and crypto by default. Futures and forex work with the right data feeds (Interactive Brokers, OANDA). Architecture is asset-class neutral.
Stop letting emotion pick your setups for you.
Book a Pipeline Audit. We'll codify your edge into a rubric, build the agent, and quote a fixed-price implementation.