The full n8n canvas as it runs in production.
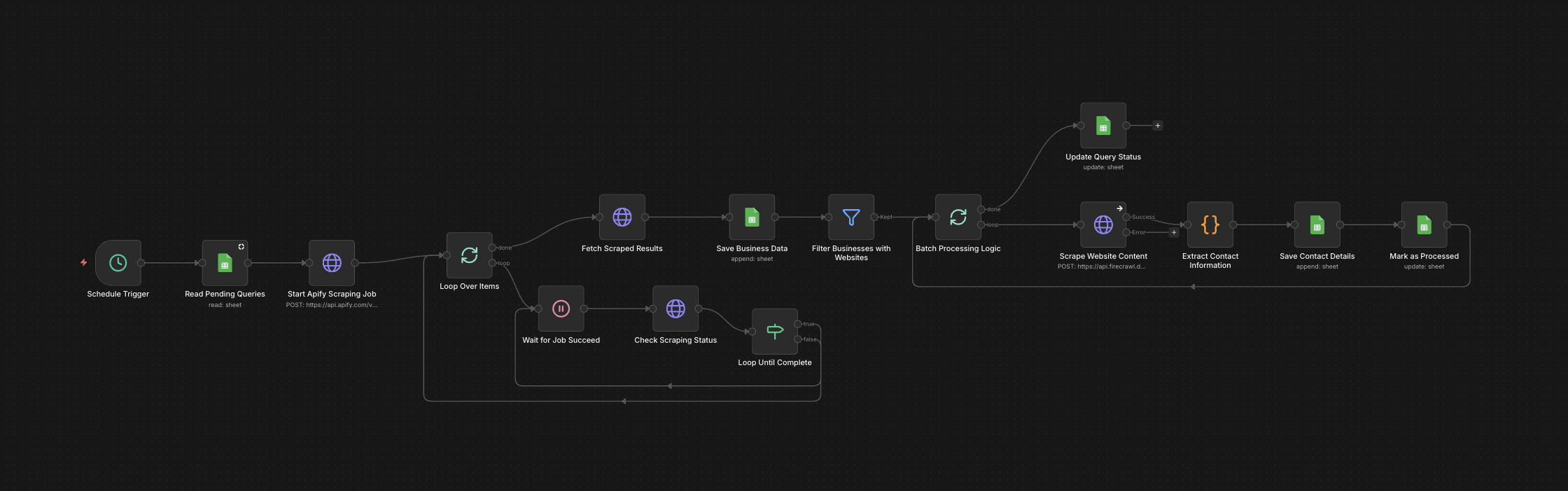
Firecrawl Is Powerful, but Wiring It Per Workflow Is Tedious
Firecrawl handles JavaScript-rendered pages, anti-bot protection, and full-site crawling — the cases the free HTTP scraper can't. It's the right tool for hard scraping. But integrating Firecrawl from scratch into every new workflow takes a day, and most teams end up with three slightly different Firecrawl integrations across their workflow library.
The fix is a wrapper component — a single n8n sub-flow that handles authentication, schema management, error handling, and retry logic. Drop the wrapper into any workflow that needs deep scraping. Pass a URL and an extraction intent. Get structured JSON back.
This wrapper has extraction schemas pre-tuned for the most common B2B targets — company homepages, service pages, team pages, blog indexes, pricing pages. For each, the schema returns the fields most workflows actually need. No schema-tuning per workflow.
The result is a building block. Lead gen pipelines, outbound enrichment, competitive research, and content workflows all use the same node with different intent flags. Adding deep scraping to a workflow becomes a 10-minute task, not a day.
URL In, Pre-Structured JSON Out
Built on n8n. The wrapper accepts a URL and an extraction intent (homepage, services, team, blog, pricing, custom). For pre-tuned intents, the wrapper invokes Firecrawl with the right schema. For custom intents, it accepts a user-supplied schema.
Firecrawl runs the scrape and returns markdown plus structured fields. The wrapper post-processes — normalises field names, handles missing values, deduplicates link lists, validates structured fields. Output ships as clean JSON. Failure handling and retry logic are baked in. Reuse rate across our workflows: 5+ different production pipelines per client.
From URL to Structured JSON via Firecrawl
URL + Intent Input
Workflow passes a URL and an extraction intent flag. Pre-tuned intents — homepage, services, team, blog, pricing — load the right schema. Custom intents accept a user-supplied schema.
Firecrawl Invocation
Wrapper invokes Firecrawl's /crawl or /scrape endpoint with the right config. Authentication, rate limits, and retry-with-backoff handle automatically.
Markdown + Structured Return
Firecrawl returns the scraped page(s) as markdown plus extracted structured fields (where the schema specified them). Both flow into the post-processing layer.
Field Normalisation
Field names normalise to a canonical schema. Missing fields default sensibly. Multi-page crawls aggregate into a single output object with per-page results indexed by URL.
Validation and Cleanup
Structured fields validate against expected types. Email addresses, phone numbers, and URLs cleanup. Duplicates remove. The output is workflow-ready, not raw.
Structured JSON Output
Output ships as clean JSON to the next workflow node. Failure cases (404s, anti-bot blocks Firecrawl can't bypass) flag with structured error codes.
What This Wrapper Does That Raw Firecrawl Doesn't
Pre-Tuned Extraction Schemas
Five common intents (homepage, services, team, blog, pricing) ship with extraction schemas tuned for the most-needed fields. Drop in, no schema-tuning required.
One-Call Interface
Single n8n sub-flow handles auth, retry, error handling, and post-processing. New workflows wire deep scraping in 10 minutes instead of a day.
Full-Site Crawling
Multi-page crawls aggregate into a single output object. Useful for grabbing a company's full service catalogue or every team-member bio in one call.
Anti-Bot Bypass
Firecrawl handles Cloudflare, DataDome, and most enterprise anti-bot. The wrapper exposes the underlying capability without exposing the API complexity.
Structured Field Validation
Output fields validate against expected types. Bad data flags before it contaminates downstream workflows.
Cost Visibility
Each scrape logs Firecrawl credit usage. Monthly cost projections become predictable. Most teams budget $50-$200/month at typical lead-gen volumes.
Before vs. After: What Changes When the Wrapper Ships
Engineering team has three Firecrawl integrations in three workflows. Each was wired separately. Schemas drift. Error handling is inconsistent. Adding deep scraping to a fourth workflow takes a day. Maintenance overhead grows quarterly.
Single Firecrawl wrapper sub-flow lives in the n8n library. Every workflow that needs deep scraping references it. Schemas centralise. Error handling is identical. Adding deep scraping to a new workflow is a 10-minute drag-and-drop. Maintenance overhead drops 70%.
Live in 1 Week
Days 1-2 — Firecrawl Setup and Auth
Wire Firecrawl API authentication. Configure rate limits and credit budget alerts. Verify the wrapper runs against three sample URLs across the pre-tuned intents.
Days 3-4 — Pre-Tuned Schemas
Build extraction schemas for the five common intents. Test each against ten representative URLs. Tune for field coverage and accuracy.
Days 5-7 — Validation and Reuse
Build the validation layer and error handling. Document the wrapper interface for reuse. Migrate one existing workflow to use the new wrapper as a proof point.
The Right Fit — and When It Isn't
Right fit for any team running multiple n8n workflows that need deep scraping — outbound agencies, lead gen platforms, competitive intelligence operations, content research workflows. Pairs with the free website scraper for tiered routing.
Not a fit for teams running one-off scraping jobs — Firecrawl's raw API is fine for one-off use. Not a fit for organisations on extreme cost constraints — Firecrawl is paid per credit and even with the wrapper there's a cost floor.
Frequently Asked Questions
What's the cost per scraped site?+
Roughly $0.05-$0.20 per site depending on page depth. A full company homepage + 5 deep pages is typically $0.10. Compare to the engineering time saved versus wiring Firecrawl from scratch — usually pays back in week one.
Can I use a different scraping backend?+
Yes. The wrapper architecture is backend-agnostic. We've shipped versions on top of ScraperAPI, Bright Data, and Apify with the same interface. Firecrawl is the default because pricing and quality are best-in-tier for B2B targets.
How do you handle sites with auth or paywalls?+
We don't, by default. Firecrawl bypasses public anti-bot but won't bypass authentication. For paywalled or auth-required sites, we use Puppeteer with managed cookies as a separate workflow.
Can the schemas be customised per client?+
Yes. The five pre-tuned intents are starting points. We typically add 2-3 client-specific schemas during onboarding for verticals or page types unique to the client's workflows.
Stop wiring Firecrawl from scratch in every new workflow.
Book a Pipeline Audit. We'll deploy the wrapper into your n8n instance and quote a fixed-price install with extraction schemas tuned for your verticals.