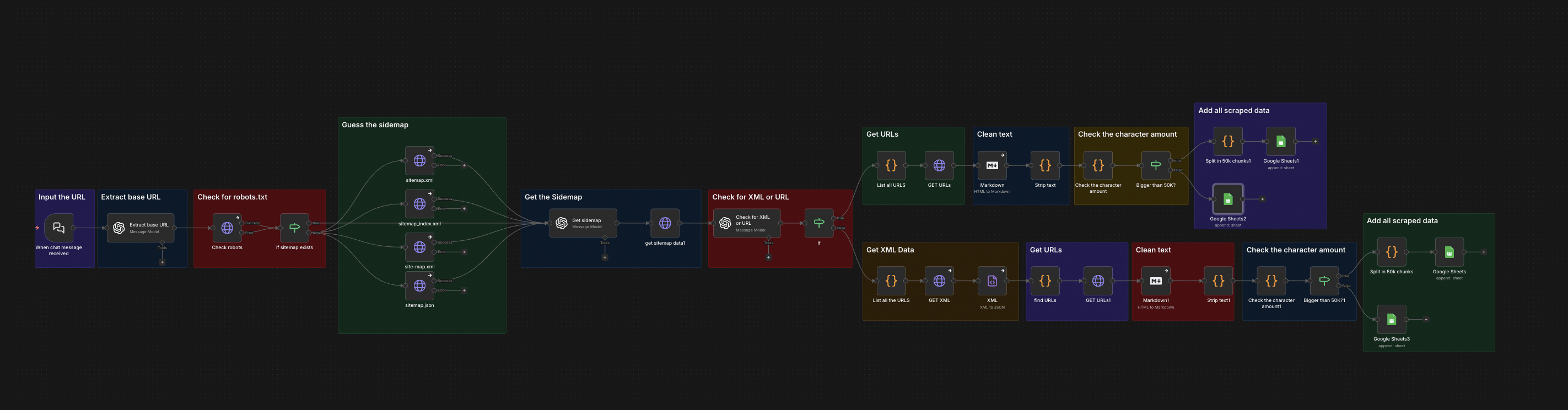
The full n8n canvas as it runs in production.
Most Scraping Costs You Pay Are Unnecessary
Apify, Firecrawl, ScraperAPI, Bright Data — all priced for hard scraping cases. Sites with anti-bot protection, JavaScript-rendered content, captcha walls, geographic blocks. The pricing reflects the actual difficulty of those cases.
But 80% of scraping in real workflows isn't hard. Static HTML pages. Public data. No anti-bot measures. Standard headers work. Yet most teams default to paid scraping tools because that's how the workflow was built originally — and the monthly bill creeps up.
The fix is a tiered approach. Easy scraping (static HTML, no anti-bot) runs through a free HTTP-and-parser node. Hard scraping (rendered JS, anti-bot, captcha) routes to paid tools. Most workflows discover that 80% of their scraping volume can move to the free tier.
This is the free-tier scraper. HTTP request, HTML parse, structured extraction. Drop into any n8n workflow. Replaces 60-80% of paid scraping volume in most operations. Annual savings: $1,500-$10,000 depending on workflow scale.
HTTP In, Structured Data Out
Built on n8n. The trigger accepts a URL plus a structured extraction schema (CSS selectors or XPath expressions for the fields needed). HTTP request fires with rotated user agents and configurable rate limits. Response HTML parses through cheerio.
The extraction schema runs against the parsed DOM. Each field in the schema produces a value or null. Output flows as structured JSON. Failure handling — non-200 responses, malformed HTML, missing fields — logs to a retry queue for inspection. Total cost per scrape: $0. Speed: 1-3 seconds per page.
From URL to Structured JSON
URL + Schema Input
Workflow passes a URL and an extraction schema (CSS selectors per field). Examples: { title: 'h1', price: '.price', desc: '.product-description' }.
HTTP Request
Request fires with rotated user agents and configurable headers. Rate limits respect. Retries on 429 (rate limit) or 503 (service unavailable) with exponential backoff.
HTML Parse
Response body parses through cheerio. Edge cases (malformed HTML, redirects, character encoding issues) handle silently. Output is a queryable DOM tree.
Schema Extraction
Each field in the extraction schema queries against the DOM. Missing fields return null with a flag. Multi-value fields (lists, arrays) return as JSON arrays.
Validation Layer
Optional validation rules check field types and value ranges. Out-of-range or missing values flag for downstream review. Prevents bad data from contaminating downstream workflows.
Structured Output
Output ships as structured JSON to the next workflow node. Failed scrapes log with URL, error type, and retry status. Successful scrapes update a manifest sheet for audit.
What This Scraper Does That Paid Tools Don't
Zero Per-Request Cost
No API fees. No per-page pricing. Annual savings of $1,500-$10,000 depending on volume vs. paid alternatives.
80% of Common Cases
Static HTML, public data, no anti-bot — the bulk of real-world scraping. Where the case gets hard, the workflow can fall back to a paid tool seamlessly.
Structured Schema Extraction
CSS selectors or XPath define the extraction schema. Fields return as structured JSON, not raw HTML. Drop straight into downstream workflows.
Rate-Limit and Retry
Configurable rate limits per domain. Automatic retry with backoff on 429/503. Polite scraping that doesn't get blocked.
Tiered Routing
Pair with the Firecrawl scraper case study for tiered routing. Easy URLs run through this node. Hard URLs route to Firecrawl. Cost optimises automatically.
Reusable Component
Drop into any workflow that needs scraping. Lead gen pipelines, price monitoring, content snapshots, competitive intelligence — all use the same node with different schemas.
Before vs. After: What Changes When You Stop Paying for Easy Scrapes
Retail ops team runs price monitoring across 80 competitor pages every 6 hours. Apify charges $0.005 per scrape. Monthly cost: $580. The team has been paying it for two years without questioning the architecture.
Same workflow, replaced with the free HTTP scraper. Same scrape volume. Same data quality. Monthly cost drops to $0 plus n8n compute. The Apify subscription gets cancelled. Annual savings: $7,000.
Live in 1 Week
Days 1-2 — Audit Existing Scraping
Audit the current scraping workflows. Categorise URLs as easy (static, public, no anti-bot) versus hard (JS-rendered, captcha, anti-bot). Most teams find 60-80% are easy.
Days 3-5 — Build the Scraper Node
Build the HTTP-request and parser logic. Wire user-agent rotation, rate limits, and retry-with-backoff. Test against the audit's easy URLs.
Days 6-7 — Schema Migration and Cutover
Migrate existing schemas from the paid tool format to CSS selectors. Run the new scraper in parallel for one week to verify data quality. Cancel the paid subscription.
The Right Fit — and When It Isn't
Right fit as a building block inside any workflow that scrapes static HTML — price monitoring, lead gen, content snapshots, competitive intel, basic data extraction. Pairs with paid scrapers for the harder cases.
Not a fit for JavaScript-rendered SPAs, sites with strong anti-bot protection (Cloudflare, DataDome), or pages requiring authentication. Those need Firecrawl, Apify, or browser-automation tools. The architecture supports tiered routing so the right tool handles the right case.
Frequently Asked Questions
Won't sites block this kind of scraper?+
Most won't, with proper user-agent rotation and rate limiting. Heavy-anti-bot sites will. We tier the workflow so easy URLs go free and hard URLs go paid — the architecture handles this transparently.
How does it handle JavaScript-rendered content?+
It doesn't. JS-rendered SPAs (most modern e-commerce, social media, web apps) need a headless browser. We wire in Puppeteer or fall back to Firecrawl for those cases.
What happens when a site changes its HTML structure?+
Extracted fields return null and flag in the validation layer. The workflow can either alert or auto-fall-back to a paid tool. Schema updates are a config change, not a code edit.
Is this legal?+
Public data scraping is legal in most jurisdictions when respecting robots.txt and rate limits. We bake those into the scraper. Specific use cases should be reviewed against local data protection regs before deployment.
Stop paying for scraping you could do for free.
Book a Pipeline Audit. We'll review your scraping needs and quote a fixed-price replacement for your paid tooling.