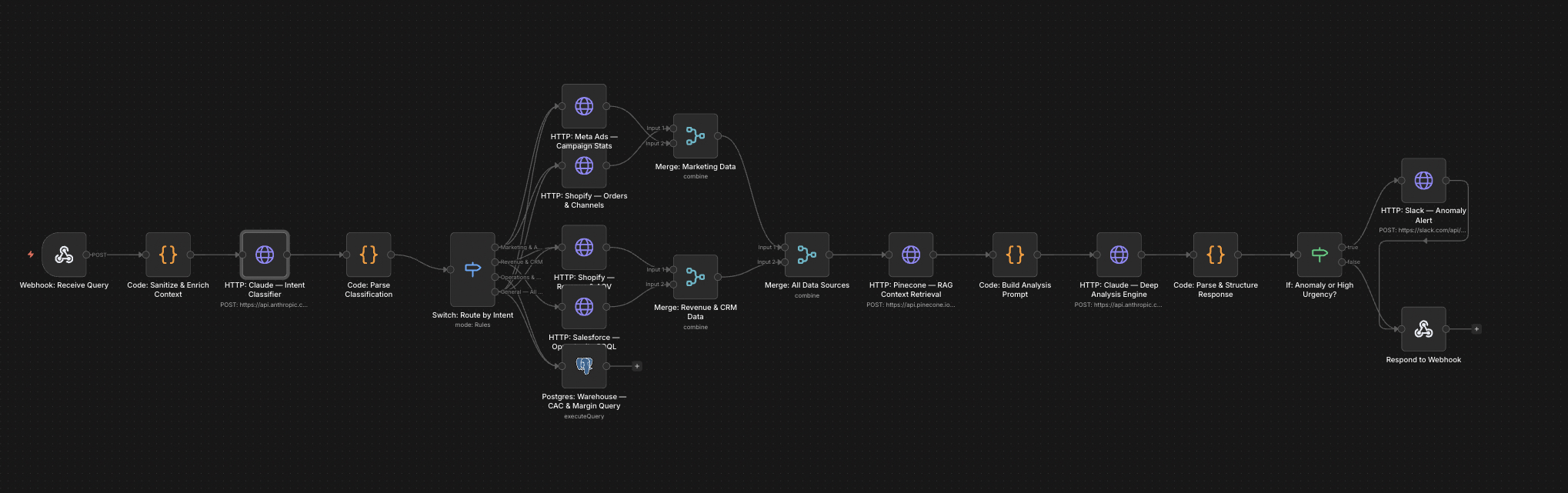
The full n8n canvas as it runs in production.
Once You Have Five AI Workflows, Your Bill Stops Making Sense
Most teams hit this around the third or fourth AI workflow they ship. The bill from OpenAI (or Anthropic, or Cohere) was $200 in month one. By month four, it's $4,800 and trending up. Nobody on the team can explain which workflow is responsible for what share of the cost.
The reason is invisible accumulation. Each workflow's prompt grew slightly over time. The team added more context for accuracy. The model got swapped for a higher-tier one when one workflow needed it but never swapped back. Token counts crept up. Nobody noticed because no single change felt big.
The fix is observability. Log every LLM call with model, tokens, cost, latency, prompt, and outcome. Attribute every call to a specific workflow. Surface dashboards showing cost per workflow per day. Alert when a workflow's cost-per-call jumps 20% over baseline. A/B test cheaper models against the existing one with quality benchmarks before swapping in production.
This system is the observability layer. Drop it in front of every LLM call across the n8n stack. Within two weeks, the team has visibility on cost attribution. Within a quarter, blended LLM cost typically drops 40% — by swapping over-provisioned models for cheaper ones where quality testing shows no degradation.
Every Call Logged, Every Cost Attributed
Built on n8n with PostgreSQL for storage and Grafana for dashboards. The logging layer is a small wrapper around the LLM API call. Every call writes a row — workflow name, model, prompt tokens, completion tokens, cost (calculated from the model's pricing), latency, and a hash of the prompt for grouping similar calls.
Postgres is the analytics warehouse. Grafana dashboards surface cost per workflow per day, model usage breakdown, latency percentiles, and prompt regression flags. Alerts fire when a workflow's average cost-per-call jumps 20% week-over-week, or when total daily spend exceeds a configured threshold. The team gets visibility before bills surprise them.
From LLM Call to Cost Attribution
Wrapper Intercepts the Call
Every LLM call across n8n routes through a wrapper sub-flow. The wrapper records timestamp, workflow name, model, and prompt before passing to the actual LLM API.
API Call and Response
The wrapped call fires to OpenAI, Anthropic, or whichever provider. Response returns. Token counts and latency capture from the response metadata.
Cost Calculation
Cost calculates from the model's per-token pricing. Pricing data lives in a config sheet that updates whenever providers change rates. Output cost stores against the call record.
Postgres Write
Full call record writes to Postgres — workflow, model, tokens, cost, latency, prompt hash, outcome flag. Async write means no latency impact on the actual workflow.
Grafana Aggregation
Grafana dashboards query Postgres for cost-per-workflow, model breakdown, latency percentiles, and regression flags. Updates every 5 minutes. Custom dashboards per workflow available.
Regression Alerts
Scheduled job compares each workflow's cost-per-call against its trailing 7-day baseline. >20% jumps alert to Slack. Daily total-spend threshold also triggers alerts when exceeded.
What This Engine Does That OpenAI's Dashboard Doesn't
Per-Workflow Attribution
OpenAI's dashboard shows total spend. This shows spend per workflow, per model, per day. Identifies the actual cost drivers in the AI stack.
Prompt Regression Detection
Hashes similar prompts together. When a workflow's prompt grows over time, average cost-per-call grows visibly. Alerts catch it before the next bill arrives.
Model A/B Testing
Run a workflow with two models in parallel for a week. Compare quality (via configured benchmarks) and cost. Swap to the cheaper model with confidence.
Latency Tracking
Per-call latency logs. Percentile-based dashboards (p50, p95, p99) show where workflows are slow. Useful for diagnosing user-facing latency issues.
Cost Forecasting
Trailing 7- and 30-day cost data feeds a simple linear forecast. End-of-month projected spend always visible. No more surprise bills.
Provider Diversification
Engine logs calls across providers (OpenAI, Anthropic, Cohere, Mistral, local models). Useful for teams diversifying providers for cost or risk reasons.
Before vs. After: What Changes When Cost Becomes Visible
Team has 7 AI workflows in production. Monthly OpenAI bill: $4,800 and trending up 12% per month. Nobody can answer 'which workflow costs the most?' or 'which prompt got more expensive last month?'. The CFO asks the same questions every month and gets vague answers.
Engine ships in week 4. By month 2, the team identifies that 3 workflows account for 78% of cost — and one of them (a content generation pipeline) was upgraded from gpt-4o-mini to gpt-4 for accuracy that wasn't actually needed. Swap back. Other smaller optimisations follow. By month 6, monthly bill is $2,900 — 40% lower with no quality loss.
Live in 5 Weeks
Week 1 — Wrapper and Postgres Setup
Build the LLM call wrapper. Set up Postgres for storage. Wire async write logic. Verify wrapper adds zero perceptible latency to existing workflows.
Week 2 — Migrate Existing Workflows
Migrate every existing LLM call in n8n to use the wrapper. Verify cost data flows for at least 7 days before building dashboards.
Week 3 — Grafana Dashboards
Build the core dashboards — cost per workflow, model breakdown, latency percentiles, daily totals. Build per-workflow drill-down dashboards for the top spenders.
Week 4 — Regression Alerts and Cost Forecasting
Build the regression detection job. Wire Slack alerts. Build the cost forecasting view. Test alerts against known-broken prompts.
Week 5 — A/B Testing Framework
Build the model A/B testing framework. Configure quality benchmarks for the team's main use cases. Run the first A/B test (typically GPT-4o vs GPT-4o-mini on a content workflow) to validate the framework.
The Right Fit — and When It Isn't
Right fit for teams running 5+ LLM workflows in production with monthly LLM spend over $1,500. Strongest fit for teams where engineering owns the AI stack and is feeling the bill creep month over month.
Not a fit for teams with one or two simple LLM workflows — the analytics overhead doesn't pay back at low volume. Not a fit for teams using third-party AI products (where the LLM calls happen inside vendor systems and aren't accessible to log).
Frequently Asked Questions
Will the wrapper add latency to my workflows?+
Async write means the wrapper adds under 5ms in most setups. Sync writes (only used when the workflow explicitly needs the cost data) add 50-100ms. Most clients use async by default.
Can I use Datadog or New Relic instead of Grafana?+
Yes. The wrapper writes to a structured log format that's tool-agnostic. We've shipped versions on Datadog, New Relic, Grafana Cloud, and Postgres + Metabase. Grafana is the default because it's lowest-cost.
What about LangSmith or LangFuse?+
Both are good purpose-built LLM observability tools. We integrate them when teams prefer hosted SaaS over self-hosted. The trade-off is per-call pricing on the SaaS tools versus a fixed cost on self-hosted Postgres + Grafana.
How does it handle prompt evaluation / quality?+
Quality benchmarks need to be configured per workflow. We typically wire 5-10 representative inputs with expected outputs. The A/B framework runs both models against these and surfaces quality scores alongside cost.
Stop being surprised by your monthly OpenAI bill.
Book a Pipeline Audit. We'll audit your current LLM workflows, scope the observability layer, and quote a fixed-price build.