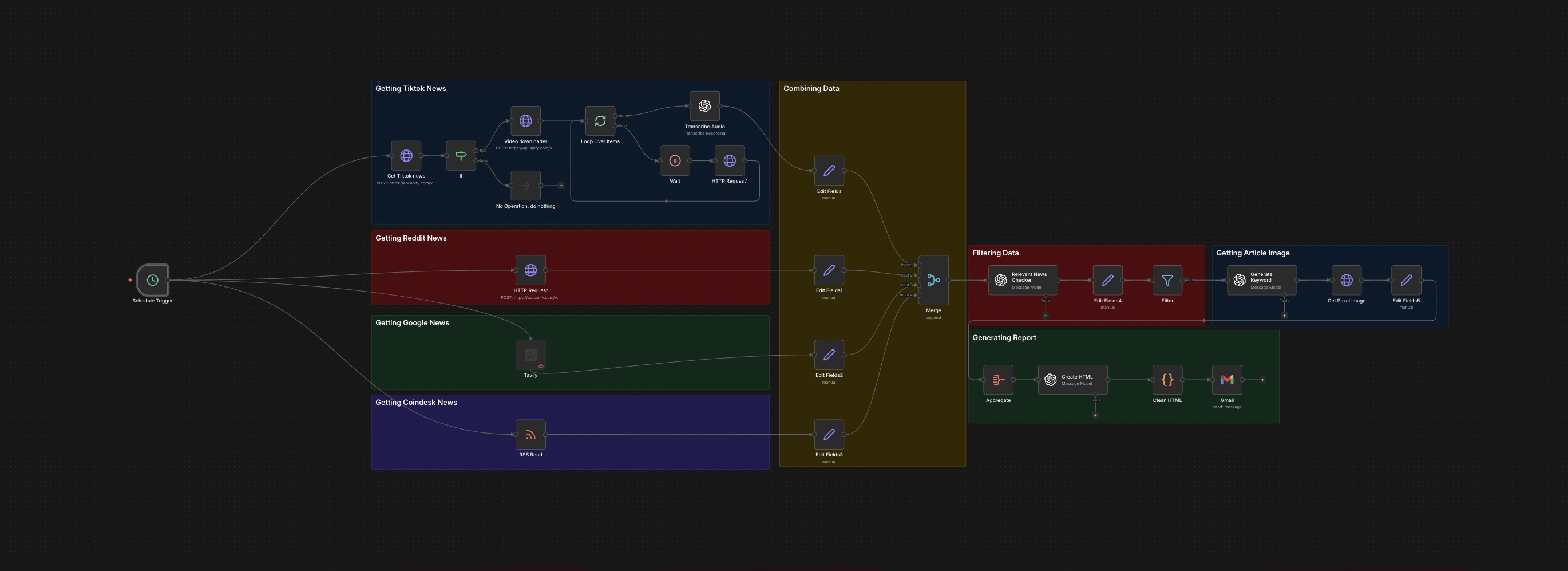
The full n8n canvas as it runs in production.
The Twelve-Tab Morning Every Trading Desk Loses
Every trading desk starts the same way. Twelve tabs. Reddit's r/CryptoCurrency. CoinDesk. The Block. CoinTelegraph. A handful of Twitter accounts. A Tavily search. A TikTok scroll. Read, copy, paste, repeat. Try to build a picture of what moved overnight while filtering rumours and recycled headlines. By the time the picture is ready, ninety minutes are gone. The information is already ninety minutes stale.
Ninety percent of the work is mechanical. Open source. Skim headline. Decide if it's noise or signal. Copy what matters. Paste into a doc. Repeat. The judgement only kicks in once the raw collation finishes. Everything before that is a job a script can do in seconds.
Two failure modes break the manual sweep. First, missing real signal because a source wasn't checked that morning. Second, acting on fake signal because a Reddit thread was treated as confirmed when it was one anonymous account repeating itself across three threads. Both cost money. The system fixes both — every source is checked on a fixed schedule, and an LLM cross-validates claims across sources before anything reaches a human.
The output is one HTML email in the inbox before the first coffee. Verified. Deduplicated. Ranked. Ready to act on. The trader gets ninety minutes back and gets earlier signal in the same move.
From Twelve Tabs to One Inbox
Built on n8n. Five parallel ingestion legs feed one judgement layer. Each leg pulls from a different source class — Reddit threads, TikTok finance creators, RSS feeds from established publications, Tavily real-time search, and a custom keyword watcher. Legs run in parallel, not sequentially. Total job time is bounded by the slowest source, not the sum of all of them.
After ingestion, every item passes a deduplication step. URL canonicalisation collapses the same story under different paths. Title fingerprinting catches near-duplicates. Then GPT-4o-mini scores each candidate from 0 to 10 — novelty, source reliability, market relevance. Items below threshold drop silently. The rest are grouped by topic, summarised in two sentences, and assembled into an HTML digest with thumbnails generated on demand. Gmail ships the email at a fixed time daily.
From Cron to Inbox: Six Steps
Scheduled Trigger Fires
An n8n cron node fires at 06:30 local. The single trigger fans out into five parallel branches — one per source class — so ingestion runs concurrently, not sequentially.
Multi-Source Ingestion
Reddit's API returns top posts from configured subreddits over the past 24 hours. Apify scrapes TikTok finance creators. RSS pulls from CoinDesk, The Block, CoinTelegraph, and others. Tavily runs a real-time search for fresh stories matching configured queries.
Deduplication and Cleaning
All items merge into one array. URL canonicalisation collapses the same story under different paths. Title fingerprinting catches near-duplicates. The clean set reduces 200 raw items to 40-60 unique stories.
AI Signal Scoring
GPT-4o-mini reads each story and outputs structured JSON: signal score 0-10, category tag, one-sentence summary. Stories below score 4 drop. The model is prompted to be ruthless — false positives cost more than missed stories.
Thumbnail Generation
For the top 8-12 stories, a thumbnail is pulled from the source's Open Graph image or generated via screenshot. Each is uploaded to Drive and a CDN URL is embedded in the email.
Digest Assembly and Delivery
An HTML template populates with ranked stories, summaries, source attributions, and thumbnails. Gmail ships to the distribution list. A copy logs to Google Sheets with timestamps for audit and comparison.
What This System Does That Manual Reading Can't
Twelve Sources, One Output
Reddit, TikTok, RSS, Tavily, and custom watchers feed one digest. No tab switching. No source juggling. No missed feeds.
Cross-Source Validation
Stories appearing in multiple independent sources score higher. Single-source rumours get flagged. Confirmed news separates from speculative noise.
Ruthless Signal Filtering
GPT-4o-mini scores every candidate against a tuned rubric. About 94% of raw items get filtered out before they reach the inbox.
Polished HTML Delivery
The final email isn't a wall of links. Each story has a thumbnail, two-sentence summary, source attribution, and click-through. Reading takes 8-10 minutes.
Configurable Source Mix
Adding a subreddit, RSS feed, or Tavily query is a one-line config change. No code edits required.
Auditable Run History
Every run logs to Google Sheets with story counts, scoring distributions, and run time. Historical performance is queryable for tuning the rubric.
Before vs. After: What Changes When News Reads Itself
The trader arrives at 07:00 and starts the manual sweep. Twelve tabs. Three coffees. Ninety to a hundred minutes of skimming. By 08:30 there's a notebook of links and a vague ranking. The market opened thirty minutes ago. Half the stories are duplicates. Two real signals got missed because the trader ran out of time before checking the smaller subreddits.
At 06:35 the digest arrives. By 06:45 the trader has read every story that matters, knows which ones are cross-validated, and has flagged three for deeper investigation. Market opens at 08:00 with the trader two hours ahead. The smaller subreddits, the TikTok creators, the long-tail RSS feeds — all checked. Nothing missed because nothing relies on a human remembering to look.
Live in 2 Weeks
Days 1-3 — Source Inventory and API Setup
We catalogue every source the desk checks manually. Reddit API credentials, Tavily account, Apify actors for TikTok, RSS feed URLs. Each source gets a config row in a Google Sheet so non-engineers can edit later.
Days 4-7 — Ingestion and Deduplication
We build the parallel ingestion legs, URL canonicalisation, and title fingerprinting. Three days of dry runs compare the system's output against the trader's manual sweep. That's how we calibrate.
Days 8-10 — AI Scoring and Prompt Tuning
GPT-4o-mini scoring wires in with an initial rubric. We iterate the prompt against historical examples until the false positive rate drops below 8%. The trader signs off before we lock it.
Days 11-14 — HTML, Delivery, and Handover
We build the responsive HTML email, wire up Gmail, set up the audit log, run end-to-end tests. The desk gets two test emails per day for the final week before launch.
The Right Fit — and When It Isn't
Right fit for any team that spends meaningful time each day collating news from multiple sources — trading desks, research firms, hedge funds, crypto desks, fintech analysts, finance media. The team has clear views on which sources are authoritative and which signals matter. The rubric is configurable, but the system can't invent it from scratch.
Not a fit for teams who want true real-time alerting on a small number of named tickers — that's a different build with sub-minute latency and push notifications. Not a fit if the team's edge is reading raw primary sources at length. The digest is for breadth, not depth.
Frequently Asked Questions
Does this work outside finance?+
Yes. The source list, search queries, and scoring rubric are config-driven. We've adapted it for legal news, biotech catalysts, and SaaS competitive intel — same architecture.
How do you keep Reddit rumours out of the digest?+
Single-source items get flagged. Stories appearing in two or more independent sources score higher. The model is prompted to discount unverified speculation, and we tune that rubric against historical examples during onboarding.
What happens when a source goes down?+
Each ingestion leg wraps in retry-with-backoff and an alert. If a source breaks, the digest still ships from the remaining legs and we get a Slack notification to fix it.
Can the digest go to Slack or Telegram instead of email?+
Yes. The delivery node is a single swap. We've shipped versions that send to Slack channels, Telegram groups, and private webhooks into a custom dashboard.
Stop reading twelve tabs at 7am to find three signals.
Book a Pipeline Audit. We'll map your sources, model the noise-to-signal ratio, and quote a fixed-price build.