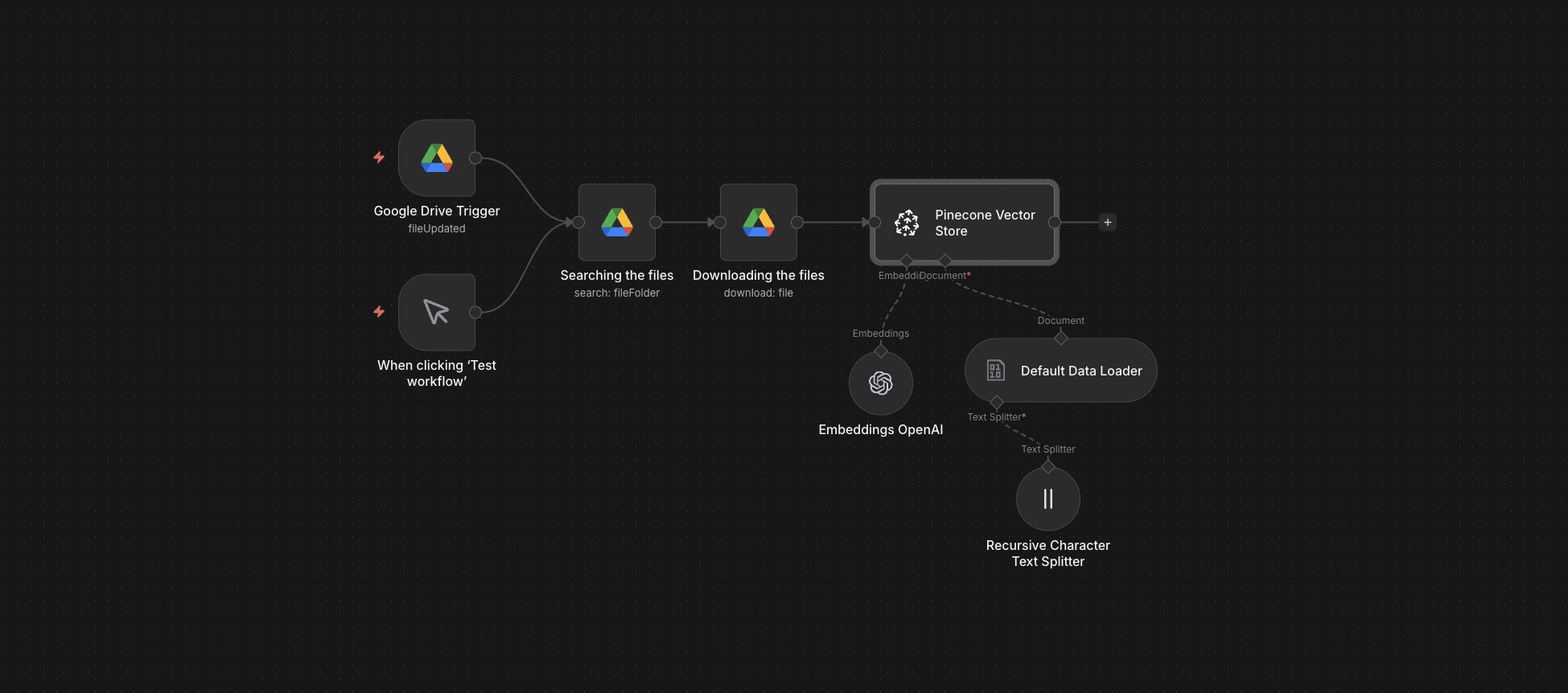
The full n8n canvas as it runs in production.
Vector Stores Don't Refresh Themselves
Every RAG system has the same hidden failure mode. The team builds it, ingests the initial docs, ships it, then stops. Three months later, half the answers are wrong because half the docs are stale and the new docs were never embedded.
Manual ingestion is the problem. Someone has to remember to run the script, point it at the new files, and verify the embedding worked. In practice, that someone gets busy. The vector store rots.
The fix is automation that doesn't depend on human memory. A Drive folder is the source of truth. Anything that lands in it gets ingested within five minutes — chunked, embedded, upserted — without anyone touching anything.
This system is the ingestion layer that pairs with the RAG bot. Together they form a knowledge pipeline that stays current as long as the team uses Drive. The wiki finally keeps up.
Folder In, Vectors Out
Built on n8n. A scheduled trigger polls a Drive folder every five minutes for new or updated files. Each new file gets downloaded, content-extracted (PDF, DOCX, TXT, MD all supported), and recursively chunked at ~500 tokens with 50-token overlap.
Each chunk runs through OpenAI's text-embedding-3-small. The resulting vectors batch in groups of 100 and upsert to Pinecone with full metadata — source filename, chunk position, content hash, last-updated timestamp. Modified files trigger replacement of old chunks. Deleted files trigger vector cleanup. The store stays clean.
From Upload to Searchable in Under 5 Minutes
Drive Watcher Polls
Scheduled trigger fires every 5 minutes. Lists files in the configured folder. Compares against a manifest of already-ingested files. Surfaces new and modified ones.
Content Extraction
Each new file downloads. PDF text extracts via pdf-parse. DOCX via docx-parser. TXT and MD pass through. Everything else gets logged as unsupported and skipped with an alert.
Recursive Chunking
Each document splits into ~500-token chunks with 50-token overlap. Chunk boundaries respect paragraph and heading breaks. Each chunk gets a stable ID derived from content hash.
Embedding Generation
Chunks batch in groups of 100 and run through OpenAI text-embedding-3-small. Cost per 1k chunks: about $0.02. Failures retry with exponential backoff.
Pinecone Upsert
Vectors upsert to Pinecone with metadata. Modified files trigger deletion of old chunk vectors before new ones write. The vector count stays accurate.
Manifest Update
After successful upsert, the file's hash and timestamp log to a manifest sheet. The next poll skips it. Total cycle time: under 5 minutes per document.
What This Pipeline Does That Manual Ingestion Doesn't
Five-Minute Freshness
From file upload to searchable vector in under five minutes. The downstream RAG bot reflects the latest docs without anyone running anything.
Multi-Format Support
PDF, DOCX, TXT, Markdown out of the box. Add PowerPoint, HTML, or scanned-with-OCR with a single node swap.
Deduplication by Hash
Content hashes prevent re-embedding unchanged docs even if the file timestamp updates. Saves embedding cost and prevents vector duplication.
Modified-File Handling
When a doc is updated, old chunks delete from Pinecone before new ones upsert. The vector store reflects the current state, not historical accumulation.
Failure Recovery
Embedding failures retry with backoff. Permanent failures log to a Slack alert with the file name. Nothing fails silently.
Cost Visibility
Every ingestion logs token count and embedding cost. Monthly summaries make the per-document cost transparent for budgeting.
Before vs. After: What Changes When the Vector Store Self-Updates
RAG bot ships in May. By July, half the queries return wrong answers. Someone realises the team has uploaded 80 new client briefs that were never embedded. Manual catch-up takes a day. Then it happens again in October.
Files drop into Drive. The bot sees them within five minutes. The team stops thinking about ingestion entirely. The vector store stays current as long as Drive is being used. Zero manual catch-up runs in twelve months.
Live in 2 Weeks
Days 1-3 — Drive and Pinecone Provisioning
Set up the Drive folder structure and Pinecone index. Decide chunk size, overlap, and metadata schema. Provision API keys and quota limits.
Days 4-7 — Ingestion Build
Build the polling trigger, content extraction, chunking, embedding, upsert. Test against a representative doc corpus. Verify chunk quality and cost per doc.
Days 8-11 — Edge Cases and Recovery
Handle modified files, deleted files, unsupported formats, large docs that exceed token windows. Wire failure alerts to Slack.
Days 12-14 — Production Cutover
Run a full ingestion against the existing doc corpus. Verify the RAG bot reflects the new vectors. Hand over the manifest sheet for ongoing audit.
The Right Fit — and When It Isn't
Right fit for any team running RAG with a doc corpus that grows or changes regularly — consultancies, research firms, agencies, product teams. Pairs with the Pinecone RAG bot or any other vector-store front end.
Not a fit for static corpora that rarely change — for those, manual one-off ingestion is fine. Not a fit for non-textual content (images, video) without an OCR or vision pre-step bolted on.
Frequently Asked Questions
What's the cost per 1,000 docs ingested?+
Roughly $0.50-$3.00 depending on doc length, plus Pinecone storage. A typical 10-page client brief costs about $0.05 to embed and store the first month.
Can it handle docs over 100 pages?+
Yes. Long docs split into chunks the same way short ones do. The only constraint is token budget per embedding call, which is way above any realistic chunk size.
What if Pinecone is down when a file uploads?+
The polling trigger is idempotent. Failed upserts log to a retry queue and try again on the next poll cycle. No data is lost.
Can we use a cheaper vector store than Pinecone?+
Yes. Pgvector on Postgres, Weaviate, or Qdrant all swap in with one node change. Pinecone is the default because it's lowest-effort to operate.
Stop running manual ingestion every time someone uploads a doc.
Book a Pipeline Audit. We'll scope your doc corpus, estimate embedding cost, and quote a turnkey ingestion pipeline that pairs with any RAG layer.