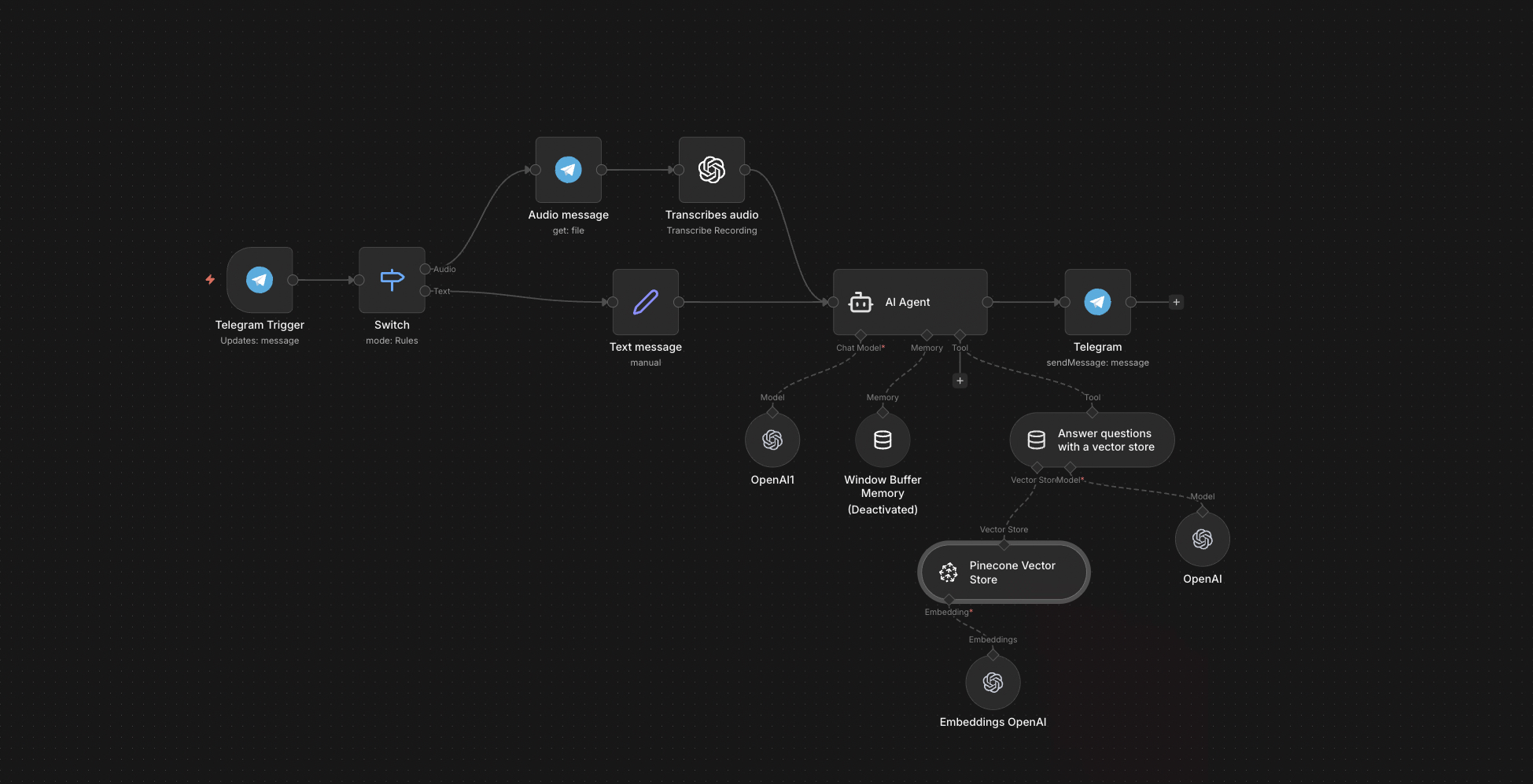
The full n8n canvas as it runs in production.
The Internal Wiki Nobody Reads
Every B2B SaaS has the same problem. The wiki has 800 pages. The handover decks are in Drive. The Slack archive holds the real answers. New hires spend two weeks reading and still don't know who handles refunds for legacy plans.
The fix everyone tries first is search. The fix that actually works is RAG — retrieval-augmented generation. The team types a question. The system pulls the three most relevant chunks from the actual docs. An LLM answers using only those chunks. No hallucination because the model has nothing else to draw on.
Two failure modes break manual document search. First, people search wrong keywords and miss relevant docs. Second, even when the right doc shows up, nobody reads forty pages to find one paragraph. RAG fixes both. The right chunks surface. The answer is one paragraph. The source is cited.
This system runs on Pinecone for the vector store and Telegram as the interface. New hires ask in plain English from their phone. Senior team members get instant answers without breaking flow. The wiki finally gets used because nobody has to read it.
Documents In, Answers Out
Built on n8n with three sides — ingestion, retrieval, response. Ingestion watches a Drive folder. New files get downloaded, chunked recursively at ~500 tokens with overlap, and embedded via OpenAI's text-embedding-3-small. Each vector lands in Pinecone with metadata pointing back to the source doc.
Retrieval starts with a Telegram message. Voice notes transcribe via Whisper. The query embeds, runs against Pinecone with top-k of 5, and returns matched chunks with similarity scores. GPT-4o-mini reads the chunks and the question, drafts an answer, and ships back to Telegram with source citations. End-to-end latency under three seconds.
From Question to Cited Answer
Drive Watcher Triggers
n8n monitors a designated Google Drive folder for new files. PDF, DOCX, TXT, Markdown all supported. New files trigger the ingestion leg.
Recursive Chunking
Each document splits into ~500-token chunks with 50-token overlap. Chunk boundaries respect paragraph breaks where possible. Each chunk gets a unique ID and source metadata.
Embedding Generation
OpenAI's text-embedding-3-small embeds each chunk. Cost per 1k chunks: under $0.02. Embeddings ship to Pinecone in batches of 100.
Vector Storage
Pinecone stores vectors with metadata — source filename, chunk position, last-updated timestamp. Metadata enables filtering by document type or recency.
Query Processing
A Telegram message arrives. Voice notes transcribe via Whisper. The query embeds and runs top-k=5 retrieval against Pinecone. A score threshold filters out weak matches.
Grounded Response
GPT-4o-mini receives the question plus retrieved chunks. Prompted to answer only from chunks, cite sources, and admit when chunks don't contain the answer. Response ships back to Telegram with source filename references.
What This System Does That Search Can't
Plain-English Querying
Voice or text. New hires ask questions the way they'd ask a senior engineer. No keywords required.
Source-Cited Answers
Every response includes the source filename and chunk position. Users can verify the answer against the original doc in one click.
Zero Hallucinations on In-Scope
The model is constrained to answer from retrieved chunks. When chunks don't contain the answer, the model says so explicitly.
Live Doc Updates
Drop a new version of a doc into Drive. Old chunks expire. New chunks embed within five minutes. The bot reflects the latest version automatically.
Telegram Voice Support
Whisper transcribes voice notes in 12+ languages. Useful for mobile workflows where typing is slow.
Audit Trail
Every query, retrieved chunks, and response logs to Google Sheets. Useful for tuning chunk size, retrieval depth, and prompt design.
Before vs. After: What Changes When Docs Answer Questions
Two weeks of new-hire onboarding. Read the wiki. Read the handover deck. Read the runbook. Slack senior teammates with basic questions and feel guilty about it. Three weeks in, still don't know who owns the legacy billing logic.
Day one, the new hire opens Telegram, types or voices the question, gets the answer with the source doc cited. Three days in, autonomous on basic flows. Two weeks in, where the previous version was three weeks in.
Live in 3 Weeks
Days 1-3 — Drive Audit and Doc Curation
We audit the docs that exist. Cull duplicates and outdated versions. Decide which folders feed the knowledge base and which stay private. Bad input means bad output — this step matters more than the build.
Days 4-8 — Ingestion Pipeline
Build the Drive watcher, chunking, embedding generation, Pinecone upsert. Run the first ingestion against existing docs. Verify chunk quality and embedding cost.
Days 9-13 — Retrieval and Response
Wire up Telegram, voice transcription, top-k retrieval, prompt template. Tune chunk size and retrieval depth against test queries from the team.
Days 14-21 — Calibration and Handover
Two weeks of supervised use. The team sends real questions. We tune the rubric, fix retrieval gaps, and lock the prompt. Documentation handover.
The Right Fit — and When It Isn't
Right fit for any team with 100+ pages of internal docs and a real onboarding cost — B2B SaaS, consulting firms, product companies, internal tooling teams. Works best when the docs are reasonably structured (paragraphs, headings, not just screenshots).
Not a fit for teams with no written documentation — RAG retrieves what exists; it can't invent knowledge. Not a fit for highly specialised technical questions where retrieval misses nuance — those still need a senior engineer.
Frequently Asked Questions
How does this avoid hallucinations?+
The model is prompted to answer only from retrieved chunks and admit when the answer isn't there. We test against a held-out question set and tune until in-scope hallucination rate drops to zero.
What if our docs are scanned PDFs?+
The pipeline handles digital PDFs out of the box. Scanned docs need OCR first — we wire in Tesseract or Google Cloud Vision as a pre-step. About $0.005 per page.
Can this query Confluence or Notion instead of Drive?+
Yes. The ingestion source is a single node swap. We've shipped versions reading from Confluence, Notion, GitHub wikis, and SharePoint.
How much does it cost to run?+
Pinecone starter plan is $70/mo for 100k vectors. Embedding cost is under $0.02 per 1k chunks. GPT-4o-mini at query time is roughly $0.0001 per query. Most teams stay under $100/mo at full usage.
Stop watching new hires re-read the wiki for two weeks.
Book a Pipeline Audit. We'll inventory your docs, scope the ingestion, and quote a fixed-price RAG bot tuned to your knowledge base.